
谷歌 Gemma 3 QAT 模型:普及消费级硬件上的先进 AI
谷歌发布了其强大的 Gemma 3 27B QAT 模型语言模型的量化版本,使最先进的 AI 能够在消费级硬件上运行。 新的量化感知训练(Quantization-Aware Training,QAT)变体大大降低了内存需求,同时保持了与全精度版本相当的性能,这标志着将先进 AI 功能引入个人设备的转折点。

将超级计算机能力带到消费级 GPU
在布鲁克林一间小公寓里,软件开发者玛雅·陈正在运行复杂的 AI 图像生成和文本分析,这些通常需要昂贵的云服务或专用硬件。 她的秘诀是什么? 一张使用了两年的 NVIDIA RTX 3090 显卡,运行着谷歌新发布的 Gemma 3 27B QAT 模型。
“这是革命性的,”陈在演示系统时解释说。 “我正在使用我已有的硬件运行相当于超级计算机级别的 AI。 在此版本发布之前,这根本不可能实现。”
陈的经历反映了谷歌 4 月 18 日声明的承诺:通过使其在广泛使用的消费级硬件上高效运行,从而普及对前沿 AI 的访问。 上个月发布的 Gemma 3 确立了其作为领先开放模型的地位,但其高内存需求限制了其在昂贵的专用硬件上的部署。 新的 QAT 变体彻底改变了这种局面。
模型压缩方面的技术突破
量化模型代表了 AI 模型压缩方面的技术突破。 传统的缩小模型尺寸的方法通常会导致显着的性能下降,但谷歌实施的量化感知训练引入了一种新方法。
与传统的训练后量化方法不同,QAT 在训练阶段本身就融入了压缩过程。 通过在训练期间模拟低精度运算,模型可以适应在最终部署时降低数值精度的情况下也能最佳运行。
一位分析过这些模型的机器学习研究员指出:“这种方法特别有效的原因在于训练方法。 通过在约 5,000 个步骤中应用 QAT,并使用来自非量化检查点的概率作为目标,他们将困惑度下降降低了 54%,与标准量化技术相比。”
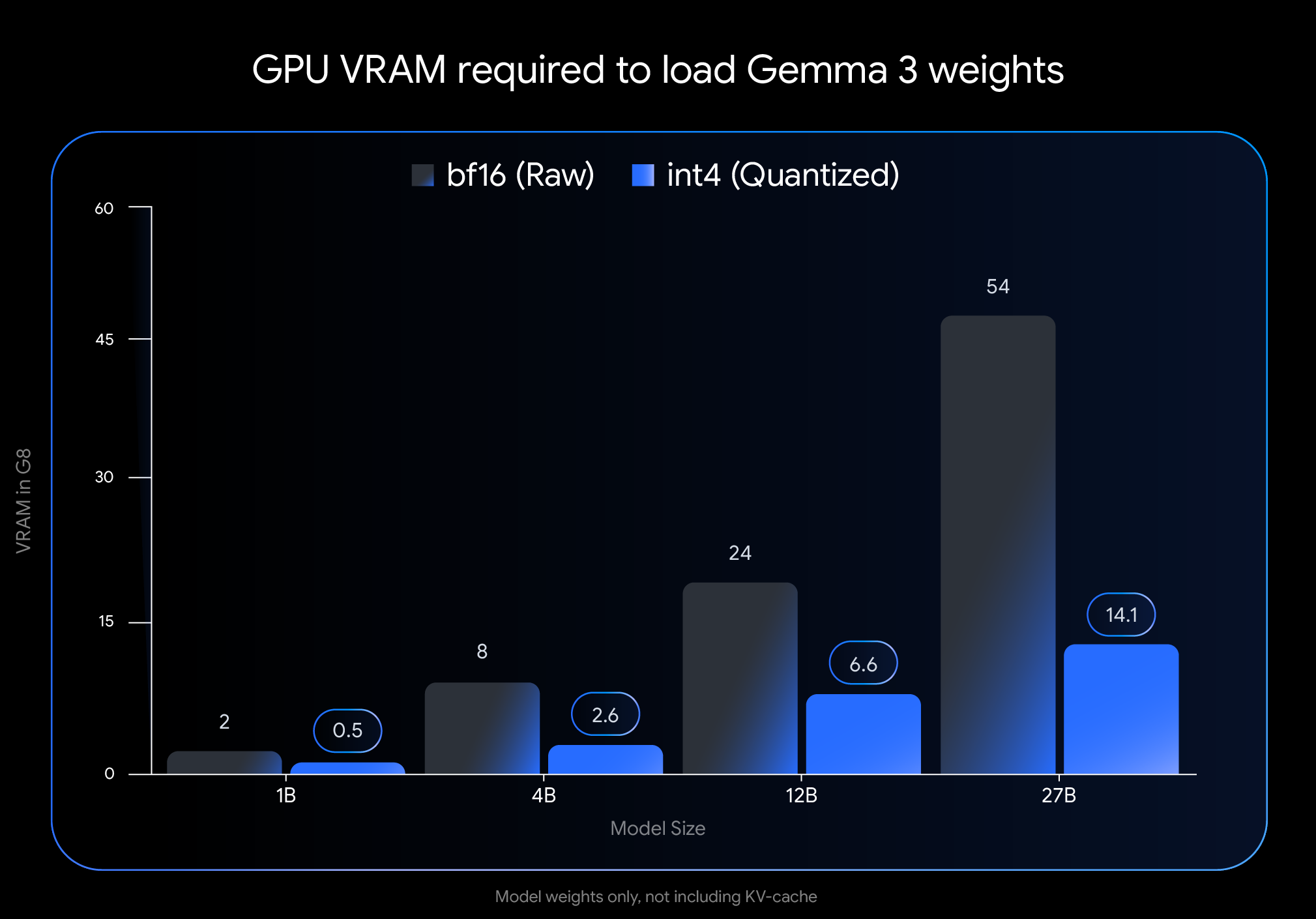
对内存需求的影响是巨大的。 Gemma 3 27B 模型的 VRAM 占用空间从 54GB 缩小到仅 14.1GB,减少了近 74%。 同样,12B 变体从 24GB 降至 6.6GB,4B 变体从 8GB 降至 2.6GB,1B 变体从 2GB 降至仅 0.5GB。
这些减少使以前无法访问的模型在消费级硬件上可行。 旗舰 27B 模型现在可以在 NVIDIA RTX 3090 等桌面 GPU 上舒适运行,而 12B 变体可以在 NVIDIA RTX 4060 等笔记本电脑 GPU 上高效运行。
真实世界的性能验证了该方法
谷歌的实施与之前模型量化尝试的不同之处在于对性能的影响最小。 独立基准测试表明,QAT 模型将精度保持在其全精度版本的 1% 以内。
在 Chatbot Arena Elo 排行榜中,这是一个基于人类偏好的、被广泛认可的 AI 模型性能衡量标准,Gemma 3 模型获得了令人印象深刻的高分。 27B 变体实现了 1338 的 Elo 分数,尽管与竞争对手相比需要的计算能力少得多,但它仍跻身顶级开放模型之列。
社区反馈证实了这些官方指标。 开发者论坛上的用户报告说,QAT 模型“感觉比其他量化变体更聪明”。 在使用具有挑战性的 GPQA diamond 指标进行直接比较时,Gemma 3 27B QAT 的性能优于其他量化模型,同时使用的内存更少。
一位将该模型集成到移动应用程序中的开发者表示:“我们在实时应用程序中看到了近乎瞬时的响应时间。 这使得 Gemma 3 适用于延迟和资源约束是关键因素的边缘部署。”
多模态功能扩展了用例
除了原始性能之外,Gemma 3 还融合了架构创新,使其功能扩展到文本处理之外。 集成视觉编码器使模型能够处理图像以及文本,尽管一些专家指出,与更大的专用系统相比,视觉理解的深度存在局限性。
另一个重大进步是支持扩展的上下文窗口——大多数变体最多支持 128,000 个 token,1B 模型支持 32,000 个 token。 这使得 AI 能够处理比大多数消费者可访问的模型更长的文档和对话。
一位熟悉该架构的机器学习工程师解释说:“交错式本地/全局注意力机制的实施大大减少了长上下文推理所需的内存占用。 这使得在不牺牲理解力的情况下,可以在消费级 GPU 上处理大量文档成为可能。”
生态系统支持促进采用
谷歌优先考虑易于集成,以与流行的开发者工具兼容的格式发布模型。 官方 int4 和 Q4_0 非量化 QAT 模型可在 Hugging Face 和 Kaggle 上获得,并得到 Ollama、LM Studio、用于 Apple Silicon 的 MLX、Gemma.cpp 和 llama.cpp 等工具的原生支持。
这种生态系统支持加速了独立开发者和研究人员的采用。 讨论论坛上充斥着在各种硬件配置和用例中成功部署的报告。
一位将该模型集成到教育应用程序中的开发者表示:“广泛的工具支持和简单的设置过程至关重要。 我们能够在数小时内本地部署,消除云成本,同时保持响应质量。”
局限性和未来方向
尽管取得了进步,但专家们指出了 Gemma 3 模型仍然面临局限性的几个领域。 虽然他们可以处理长上下文,但一些用户指出,对于复杂的分析任务,跨非常广泛的输入进行深入推理的能力仍然具有挑战性。
视觉组件虽然高效,但不如一些更大的、联合训练的多模态模型那么复杂。 这可能会影响需要细致视觉理解的任务的性能。
此外,一些机器学习研究人员指出,Gemma 3 的大部分性能来自对更强大的教师模型(可能来自谷歌专有的 Gemini 系列)的复杂知识提炼。 这种依赖性,以及训练后方法中的一些不透明性,限制了更广泛的 AI 研究社区的完全可重复性。
普及 AI 开发
该版本的发布代表着在使更广泛的开发者、研究人员和爱好者能够访问先进 AI 功能方面迈出了重要一步。 通过在常见硬件上实现本地部署,Gemma 3 QAT 模型降低了成本和技术要求方面的准入门槛。
布鲁克林开发者陈反思道:“这不仅仅是技术能力的问题。 这关系到谁能使用这些技术进行创新。 当强大的 AI 在消费级硬件上本地运行时,它为那些无法负担专用基础设施的个人和小团队打开了大门。”
随着 AI 越来越多地影响技术开发的各个方面,在本地运行复杂模型的能力可能会对主要科技公司以外的创新产生变革性影响。 谷歌对 Gemma 3 QAT 的方法表明,未来最先进的 AI 将成为一种普及化的工具,而不是一种集中化的资源。
这种愿景是否完全实现取决于技术的发展以及更广泛的开发者社区如何接受这些功能。 但就目前而言,前沿 AI 研究与实际部署之间的差距已大大缩小——这一发展可能对 AI 可访问性的未来产生深远的影响。