
字节跳动推出 Seed 1.5-VL:可媲美 Gemini Pro 2.5、颠覆性的视觉语言大模型
在多模态人工智能领域迈出的重要一步是,字节跳动 Seed 团队发布了其最新的视觉语言大模型,Seed 1.5-VL,这标志着全球人工智能竞争中的一个重要里程碑。 Seed 1.5-VL 仅激活200 亿个参数,其性能可与 Google 的 Gemini 2.5 Pro 媲美,并在广泛的真实世界视觉和交互任务中树立了业界领先(SOTA)的基准——所有这些都以显著降低的推理成本实现。
🚀 发生了什么?
在2025 年 5 月 15 日,字节跳动正式发布了 Seed 1.5-VL,这是其 Seed 多模态 AI 模型系列的最新进展。 Seed 1.5-VL 在**超过 3 万亿个高质量多模态数据(包括文本、图片和视频)**上进行了预训练,将高级视觉推理、图像理解、GUI 交互和视频分析整合到单一、简化的架构中。
与庞大的 AI 系统不同,Seed 1.5-VL 采用混合专家(MoE)架构,每项任务只激活其总共 200 亿参数的一个子集。这极大地提高了计算效率,使其非常适合在桌面、移动和嵌入式环境中运行的实时交互式 AI 应用。
尽管尺寸相对紧凑,Seed 1.5-VL 在 60 个公共评估基准中有 38 个取得了 SOTA 结果,其中包括:
- 19 个视频理解基准中的 14 个
- 7 个 GUI 智能体任务中的 3 个
在测试中,它在复杂推理、光学字符识别(OCR)、图像解释、开放词汇检测和安防视频分析等方面表现出色。
现在, Seed 1.5-VL 已通过火山引擎 API 和 Hugging Face 及 GitHub 上的开源社区向公众开放测试。
📌 主要亮点
- 多模态掌握能力:以接近人类的理解水平处理图片、视频、文本和 GUI 任务。
- 效率优先:仅激活 200 亿参数,以较低的成本提供与 Google Gemini 2.5 Pro 相当的结果。
- SOTA 成就:在 60 个公共基准中的 38 个上领先,尤其在视频和 GUI 任务方面。
- 实际应用:已在 OCR、监控分析、名人识别和比喻性图像解释等方面进行测试。
- 开放访问:火山引擎提供实时 API,arXiv 提供技术论文,GitHub 提供代码。
🔍 深度分析
架构与创新
Seed 1.5-VL 由三个主要模块构建:
- SeedViT 视觉编码器:一个拥有 5.32 亿参数的编码器,从图片和视频帧中提取丰富的特征。
- MLP 适配器:连接视觉编码器和语言模型,将图片/视频特征转换为多模态 token。
- 大型语言模型:一个基于 MoE 的 200 亿参数 LLM,针对推理效率进行了优化。
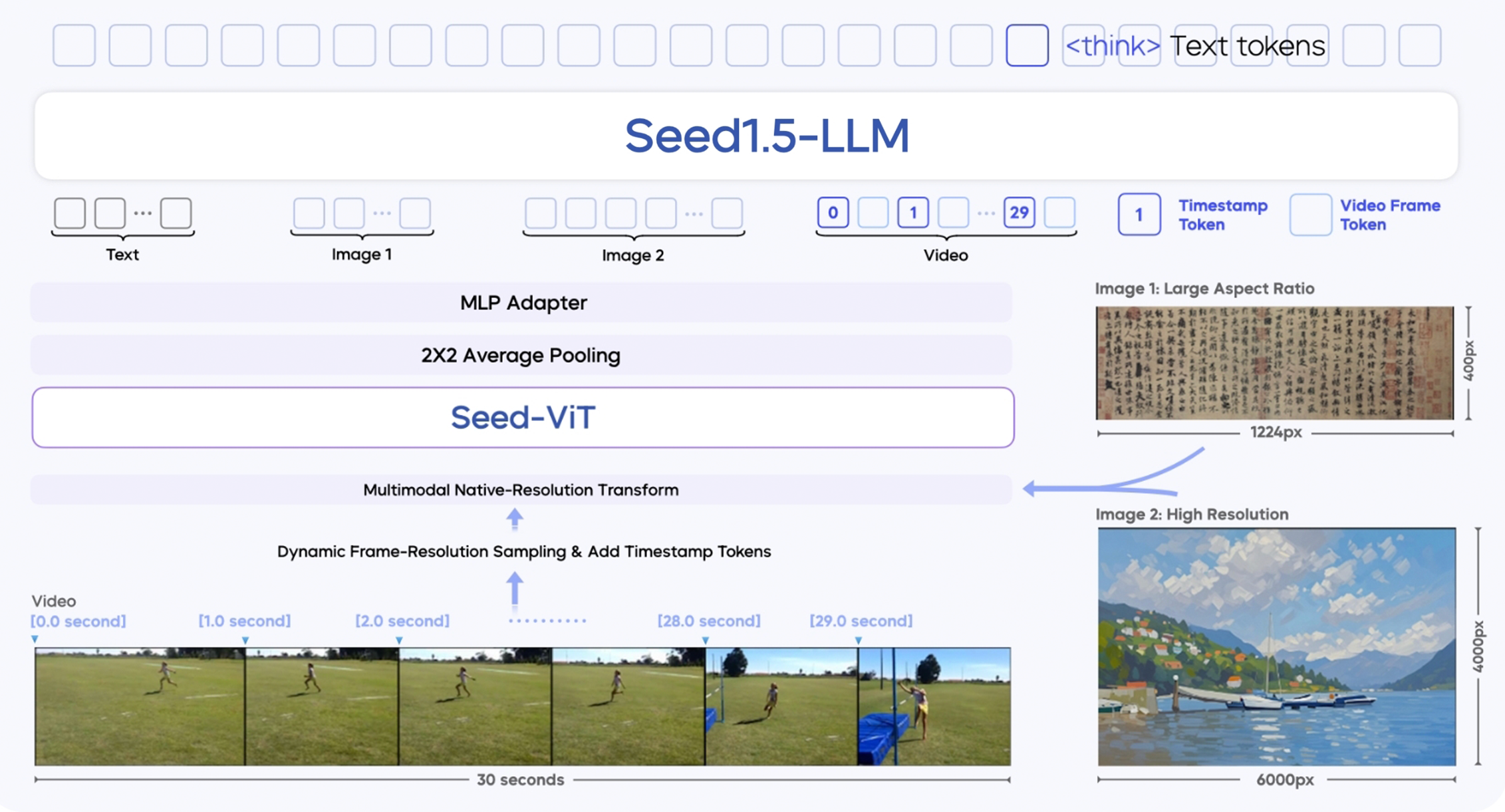
它引入了多项技术创新:
- 支持多分辨率输入:保持图片质量和精度。
- 动态帧分辨率采样:通过根据运动复杂性选择帧来改进视频理解。
- 通过时间戳 token 增强时序能力:更好地跟踪视频中的对象序列和因果关系。
- 在 3 万亿+多模态 token 上训练:提高跨领域的泛化能力。
- 后训练优化:包括拒绝采样和在线强化学习,以微调响应质量。
优势
Seed 1.5-VL 在以下方面表现出色:
- 视觉问答(VQA)和图表解释
- GUI 自动化任务,包括游戏和应用控制
- 在开放式视觉环境中的交互式推理
- 真实世界应用,如名人识别、监控和隐喻理解
它因其真实世界的鲁棒性受到赞扬,这是许多学术模型所缺乏的。一些评论者甚至称其为“非标准 powerhouse”,能够与 OpenAI 的 o4 和 Google 的 Gemini 竞争。

局限性
尽管有这些优势,Seed 1.5-VL 并非完美无瑕:
- 精细视觉挑战:在遮挡、颜色相似性或不规则排列下的物体计数方面存在困难。
- 复杂空间推理:迷宫导航或滑动拼图等任务可能导致结果不完整。
- 时序推理:在跨帧跟踪动作序列时会出现困难。
字节跳动承认这些是其未来迭代可能的目标领域。
竞争格局
Seed 1.5-VL 在人工智能军备竞赛中发布:
- Google 的 Gemini 2.5 Pro(2025 年 5 月 6 日)在多模态排行榜(LMArena)上占据主导地位。
- OpenAI 的 o3 和 o4-mini(2025 年 4 月 17 日)推动了多模态工具使用和强化学习。
- 国内竞争对手如腾讯和豆包也增强了图片和语音能力。
投资分析师看好该领域:智能体模型和多模态能力被视为下一代 AI 应用的关键驱动力,特别是在企业软件、ERP、OA、编程助手和办公工具方面。
💡 你知道吗?
- Seed 1.5-VL 可以检测监控视频中的可疑行为——这是一个很少有模型能有效处理的高级真实世界用例。
- 它是少数能够阅读隐喻性图像并解释其中抽象关系的模型之一。
- 全球只有 3 个模型(Gemini Pro 2.5、OpenAI o4、Seed 1.5-VL)目前具备实时、交互式、跨模态 GUI 控制能力。
- 字节跳动通过使用远少得多的参数实现了媲美 Gemini Pro 的性能,展示了其卓越的模型压缩和优化能力。
- Seed 1.5-VL 使用了一种原生分辨率保持转换,避免了传统视觉编码器常见的质量下降问题。
最后想法
Seed 1.5-VL 的发布是字节跳动在确立其作为全球 AI 研究领导者地位上的一个重要里程碑,特别是在多模态基础模型方面。凭借无与伦比的性能效率、强大的真实世界能力以及在关键基准上的 SOTA 成就,它不仅仅是紧跟 Google 和 OpenAI 等巨头——它正在正面竞争。
随着人工智能在各行各业的深入应用,像 Seed 1.5-VL 这样的模型将走在前沿——塑造智能体、赋能自动化,并重新定义机器的感知、理解和行动能力。
CTOL 编辑 Ken:我强烈建议您查看字节跳动官方 Seed 1.5-VL 页面上的示例——它们确实令人印象深刻。