
如何选择用于深度学习和大语言模型的GPU
为深度学习工作负载选择GPU,特别是用于训练和运行大语言模型(LLMs)时,需要考虑几个因素。这是一份全面的指南,帮助您做出正确的选择。
表:最新的主流开源大语言模型及其本地部署的GPU需求
| 模型 | 参数量 | 显存需求 | 推荐GPU |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1,342GB | NVIDIA A100 80GB ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7GB | NVIDIA RTX 3060 12GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5GB | NVIDIA RTX 3080 10GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9GB | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7GB | NVIDIA RTX 4090 24GB ×2 |
| Llama 3 70B | 70B | ~140GB (估计) | NVIDIA 3000系列,最低32GB内存 |
| Llama 3.3 (较小模型) | 不同 | 至少12GB显存 | NVIDIA RTX 3000系列 |
| Llama 3.3 (较大模型) | 不同 | 至少24GB显存 | NVIDIA RTX 3000系列 |
| GPT-NeoX | 20B | 总共48GB+显存 | 两块 NVIDIA RTX 3090 (各24GB) |
| BLOOM | 176B | 训练需40GB+显存 | NVIDIA A100 或 H100 |
选择GPU时的关键考虑因素
1. 内存需求
- 显存容量(VRAM Capacity):这可能是大语言模型最重要的因素。更大的模型需要更多的内存来存储参数、梯度、优化器状态和缓存的训练样本。
** 表:显存在大语言模型 (LLMs) 中的重要性。**
| 方面 | 显存的作用 | 为何如此关键 | 不足时的影响 |
|---|---|---|---|
| 模型存储 | 存放模型权重和层 | 高效处理所必需 | 卸载到较慢的内存;性能大幅下降 |
| 中间计算 | 存储激活和中间数据 | 使实时前向/后向传播成为可能 | 限制并行性并增加延迟 |
| 批处理 | 支持更大的批处理尺寸 | 提高吞吐量和速度 | 批处理尺寸变小;训练/推理速度变慢 |
| 并行支持 | 支持跨GPU的模型/数据并行 | 对于超大型模型(如 GPT-4)是必需的 | 限制跨多个GPU的可扩展性 |
| 内存带宽 | 提供高速数据访问 | 加速矩阵乘法等张量操作 | 在计算密集型任务中成为瓶颈 |
- 计算您的需求:您可以根据模型大小和批处理尺寸估算内存需求。
- 内存带宽:更高的带宽允许GPU显存和处理核心之间更快的数据传输。
2. 计算能力
- CUDA核心:通常核心越多,并行处理速度越快。
- Tensor核心:专门用于矩阵运算,对深度学习任务至关重要。
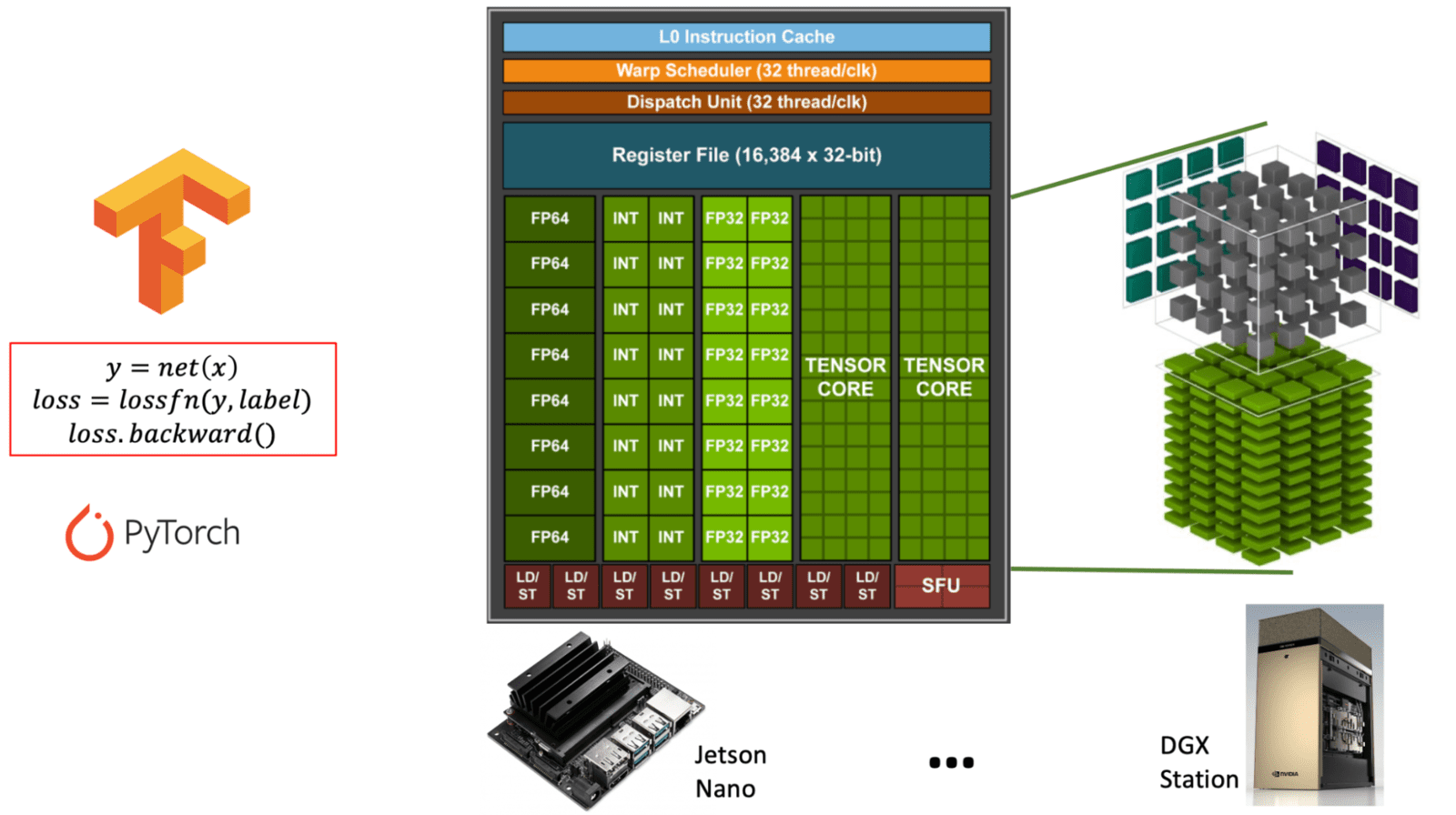
图解 NVIDIA GPU 架构中通用 CUDA 核心与专用 Tensor 核心的区别。(learnopencv.com) - FP16/INT8支持:混合精度训练可以显著加速计算并减少内存使用。
** 表:NVIDIA GPU 中 CUDA 核心与 Tensor 核心的比较。此表解释了 CUDA 核心与 Tensor 核心的用途、功能和用法,它们对于不同类型的 GPU 工作负载,尤其是在 AI 和深度学习中都至关重要。 **
| 特性 | CUDA 核心 | Tensor 核心 |
|---|---|---|
| 用途 | 通用计算 | 专用于矩阵运算(张量计算) |
| 主要用途 | 图形、物理和标准并行任务 | 深度学习任务(训练/推理) |
| 运算 | FP32、FP64、INT、通用算术运算 | 矩阵乘加运算(例如,FP16、BF16、INT8) |
| 精度支持 | FP32(单精度)、FP64(双精度)、INT | FP16、BF16、INT8、TensorFloat-32 (TF32)、FP8 |
| 性能 | 通用任务性能适中 | 矩阵密集型任务性能极高 |
| 软件接口 | CUDA 编程模型 | 通过 cuDNN、TensorRT 或框架(例如 PyTorch、TensorFlow)等库访问 |
| 可用性 | 存在于所有 NVIDIA GPU 中 | 仅存在于较新的架构(Volta 及更新版本)中 |
| AI 优化 | 有限 | 高度优化用于 AI 工作负载(可加速 10 倍以上) |
3. GPU间通信
- NVLink:如果在多GPU环境下运行,NVLink提供比PCIe快得多的GPU到GPU通信速度。
NVLink 是 NVIDIA 开发的一种高速互连技术,旨在实现 GPU 之间的快速通信(有时也包括 GPU 和 CPU 之间)。它通过提供显著更高的带宽和更低的延迟来克服传统 PCIe (Peripheral Component Interconnect Express) 的局限性。
** 表:NVLink Bridge 及其用途概述。此表概述了 NVLink 在基于 GPU 的计算(特别是 AI 和高性能工作负载)中的功能、优势和关键规格。 **
| 特性 | NVLink |
|---|---|
| 开发者 | NVIDIA |
| 用途 | 使多个 GPU 之间实现快速直接通信 |
| 带宽 | 最新版本(例如 NVLink 4.0)总计高达 600 GB/s |
| 与 PCIe 相比 | 快得多(PCIe 4.0:总计约 64 GB/s) |
| 延迟 | 低于 PCIe;提高多 GPU 效率 |
| 用例 | 深度学习 (LLMs)、科学计算、渲染 |
| 工作原理 | 使用一个 NVLink bridge(硬件连接器)连接 GPU |
| 支持的 GPU | 高端 NVIDIA GPU(例如 A100、H100、受限支持的 RTX 3090) |
| 软件 | 与支持 CUDA 的应用程序和框架兼容 |
| 可扩展性 | 允许多个 GPU 更像一个大型 GPU 一样工作 |
** NVLink 为何对 LLMs 和 AI 至关重要 **
- 模型并行性:大型模型(例如 GPT 式 LLMs)太大,一个 GPU 放不下。NVLink 允许 GPU 高效地共享内存和工作负载。
- 更快的训练和推理:减少通信瓶颈,提升多 GPU 系统的性能。
- 统一内存访问:与 PCIe 相比,使得 GPU 之间的数据传输几乎无缝,提高同步和吞吐量。
- 多卡训练:对于跨多个GPU的分布式训练,通信带宽变得至关重要。
摘要表:分布式训练中 GPU 间通信的重要性
( 表:GPU 间通信在分布式训练中的作用。此表概述了快速 GPU 到 GPU 通信的需求场景以及它对于可扩展、高效训练深度学习模型为何至关重要。 **)
| 分布式训练任务 | 为何 GPU 间通信重要 |
|---|---|
| 梯度同步 | 确保数据并行设置中的一致性和收敛 |
| 模型分片 | 实现模型并行架构中数据的无缝流动 |
| 参数更新 | 保持模型权重在 GPU 之间同步 |
| 可扩展性 | 允许高效利用额外的 GPU 或节点 |
| 性能 | 减少训练时间并最大限度利用硬件资源 |
4. 功耗和散热
- TDP (散热设计功耗):性能更高的GPU需要更多电力并产生更多热量。
- 散热方案:确保您的散热系统能够应对多个高性能GPU产生的热量。
常用GPU选项比较
** 表:用于深度学习的 NVIDIA GPU 特性比较。此表比较了 RTX 4090、RTX A6000 和 RTX 6000 Ada 的关键规格和功能,突出显示它们在深度学习工作负载中的优势。 **
| 特性 | RTX 4090 | RTX A6000 | RTX 6000 Ada |
|---|---|---|---|
| 架构 | Ada Lovelace | Ampere | Ada Lovelace |
| 发布年份 | 2022 | 2020 | 2022 |
| GPU 显存 (VRAM) | 24 GB GDDR6X | 48 GB GDDR6 ECC | 48 GB GDDR6 ECC |
| FP32 性能 | ~83 TFLOPS | ~38.7 TFLOPS | ~91.1 TFLOPS |
| Tensor 性能 | ~330 TFLOPS (FP16, 启用稀疏计算) | ~312 TFLOPS (FP16, 稀疏计算) | ~1457 TFLOPS (FP8, 启用稀疏计算) |
| Tensor Core 支持 | 第 4 代 (支持 FP8) | 第 3 代 | 第 4 代 (支持 FP8) |
| NVLink 支持 | ❌ (无 NVLink) | ✅ (双向 NVLink) | ✅ (双向 NVLink) |
| 功耗 (TDP) | 450W | 300W | 300W |
| 尺寸 | 消费级 (双槽) | 专业工作站级 (双槽) | 专业工作站级 (双槽) |
| ECC 显存支持 | ❌ | ✅ | ✅ |
| 目标市场 | 爱好者 / 专业消费者 | 专业人士 / 数据科学家 | 企业 / AI 工作站 |
| 建议零售价 (约) | $1,599 USD | $4,650 USD | ~$6,800 USD (按供应商不同) |
RTX 4090
- 架构:Ada Lovelace
- CUDA核心:16,384
- 显存:24GB GDDR6X
- 优点:性能价格比最高,非常适合单GPU工作负载
- 局限性:不支持NVLink,显存小于专业级选项
- 最适合:中等规模模型的单GPU训练,预算有限的研究人员
RTX A6000
- 架构:Ampere
- CUDA核心:10,752
- 显存:48GB GDDR6
- 优点:大显存容量,支持NVLink,专业级稳定性
- 局限性:原始性能低于更新的显卡
- 最适合:内存密集型工作负载,需要NVLink的多GPU设置
RTX 6000 Ada
- 架构:Ada Lovelace
- CUDA核心:18,176
- 显存:48GB GDDR6
- 优点:结合了最新架构、大显存和NVLink
- 局限性:价格较高
- 最适合:预算不是主要考虑因素、追求极致性能的设置
专用硬件选项
SXM接口GPU
** 表:SXM 与 PCIe 接口 GPU 的比较。此表概述了 SXM 相较于标准 PCIe 在深度学习、HPC 和数据中心应用中的主要区别和优势。 **
| 特性 | SXM 接口 | PCIe 接口 |
|---|---|---|
| 连接类型 | 直接插槽接口(非通过 PCIe 插槽) | 插入 PCIe 插槽 |
| 供电能力 | 每块 GPU 可达 700W+ | 通常限制在 300–450W |
| 散热设计 | 通过定制散热器优化散热,支持液冷选项 | 标准风扇风冷 |
| 带宽/延迟 | 支持 NVLink,具有更高带宽和更低延迟 | 受限于 PCIe 总线速度 |
| GPU 互连 | 多个 GPU 之间通过高带宽 NVLink 网格互连 | 通过 PCIe 进行低带宽的点对点互连 |
| 尺寸和集成 | 设计用于密集型服务器环境(例如 NVIDIA HGX) | 适用于工作站或标准服务器机架 |
| 性能可扩展性 | 多 GPU 配置下可扩展性极佳 | 受 PCIe 总线和电源限制 |
| 目标应用场景 | 数据中心、AI 训练、HPC、云平台 | 桌面、工作站、轻量级企业工作负载 |
- 选项:V100, A100, H100 (带 SXM2/SXM4/SXM5 连接器)
- 优点:比PCIe版本有更高的功耗限制和带宽
- 用于:NVIDIA DGX 系统等高端服务器平台
多节点方案
- 支持每节点4-8块GPU的服务器平台
- 例如:Dell C4140, 浪潮 Inspur 5288M5, GIGABYTE T181-G20
决策框架
- 首先确定您的内存需求
- 如果您的模型无法放入显存,性能就变得无关紧要了 ** 表:理解深度学习中的显存不足 (OOM) 错误。此表解释了导致 OOM 错误的原因、为何发生以及 GPU 显存限制如何影响模型训练和推理。 **
| 方面 | 解释 |
|---|---|
| 什么是 OOM? | “Out Of Memory” 错误——当模型或批次无法放入 GPU 显存时发生。 |
| 根本原因 | 模型权重、激活和数据超过了可用的 GPU 内存。 |
| 发生时机 | 模型初始化、前向传播、反向传播或加载大批次数据时。 |
| 受影响组件 | 模型参数、优化器状态、激活图、梯度。 |
| GPU 显存 (VRAM) | 有限的资源,决定了模型的规模或复杂程度。 |
| 首要检查 | 总是比较模型大小 + 批次需求与可用显存。 |
| 典型触发原因 | - 模型过大 - 批次尺寸过大 - 未使用混合精度 - 内存泄漏 |
| 缓解策略 | - 减小模型大小 - 减小批次尺寸 - 使用梯度检查点 (gradient checkpointing) - 应用混合精度 (FP16/8) - 使用更大或更多的 GPU |
-
确定您的通信需求
- 需要多GPU训练吗?需要NVLink吗?还是PCIe就足够了?
-
匹配您的预算
- 追求最高性价比:RTX 4090
- 内存敏感型工作负载但预算适中:A6000
- 追求顶尖性能和大显存:RTX 6000 Ada
-
考虑长期的研究方向
- 对于不断演进、模型可能变大的研究需求:选择显存容量更大的选项
实际部署技巧
- 为学术研究购买时,确保供应商能提供用于报销的正规发票
- 如果预计有不同的工作负载,考虑异构设置
- 对于多卡系统,运行实验时使用
CUDA_VISIBLE_DEVICES指定显卡 ** 表:CUDA_VISIBLE_DEVICES在多 GPU 管理中的作用。此表展示了此变量的工作原理、为何有用以及它在哪些场景下可改善 GPU 分配和效率。 **
| 方面 | 描述 |
|---|---|
| 功能 | 控制哪些 GPU 对一个进程可见 |
| 语法示例 | CUDA_VISIBLE_DEVICES=0,1 python train.py — 仅使用 GPU 0 和 1 |
| 设备重映射 | 内部将列出的设备映射到逻辑 ID(例如,0 变为 cuda:0) |
| 隔离 | 防止在共享 GPU 服务器上并发作业或用户之间发生冲突 |
| 性能优化 | 允许精细调整 GPU 分配以实现负载均衡 |
| 分布式训练 | 对于按节点或按工作进程分配正确的 GPU 至关重要 |
| 调试/测试 | 可用于在特定 GPU 上测试代码或避开有问题的 GPU |
| 动态 GPU 使用 | 使脚本能够在不修改代码的情况下在不同的 GPU 集上运行 |
- 在购买前彻底测试您的工作负载,确定实际的内存需求
通过仔细评估这些因素与您特定的研究需求和预算限制,您可以为您的深度学习和LLM开发环境选择最合适的GPU方案。